



Large language models (LLMs) have revolutionized artificial intelligence (AI), enabling applications across various domains, from content generation to solving specialized problems. However, their performance depends on continuous refinement through training to achieve exceptional capabilities.
One of the most effective ways to enhance these models is to fine-tune them with domain-specific data, which improves accuracy, relevance, and contextual understanding. Fundamentally, the key to the success of fine-tuning is high-quality labeled data.
Well-labeled data helps the model generate reliable and meaningful outputs tailored to its intended applications.
How can you get high-quality datasets? Dive into this article for expert insights on data labeling strategies that empower LLM makers and AI enthusiasts to unlock the full potential of fine-tuned LLMs!
What are Fine-tuning, LLMs and Fine-tuned LLMs?
Definition of fine-tuning
Fine-tuning is the process of taking pre-trained large language models like the GPT series from OpenAI and further training them on domain-specific datasets. This process allows fine-tuned LLMs to adapt to specialized applications, enhancing performance in niche areas while retaining the general knowledge acquired during initial training.
Fine-tuning bridges the gap between generic pre-trained models and specific requirements, ensuring that the language model aligns more closely with human expectations. However, the approach to fine-tuning varies based on specific goals. The primary methods of LLM fine-tuning include unsupervised fine-tuning, supervised fine-tuning, and instruction fine-tuning.
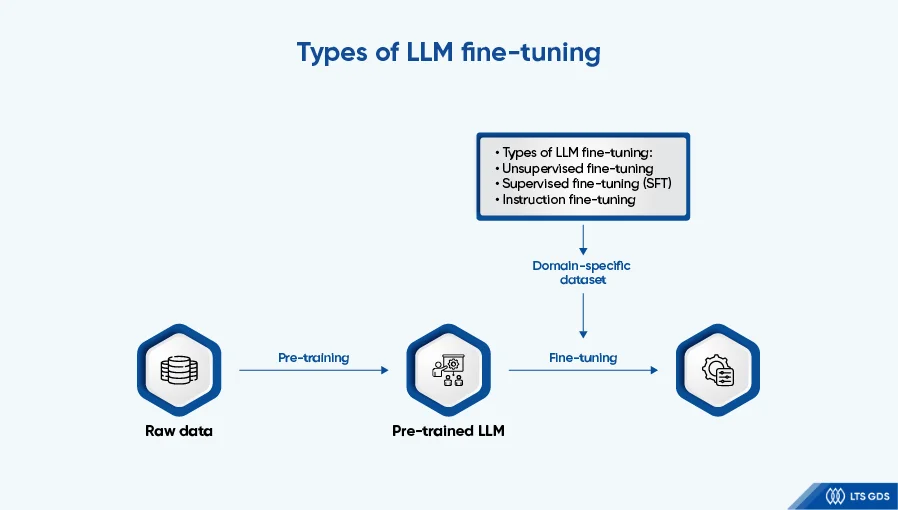
Types of LLM fine-tuning
Unsupervised fine-tuning
Unsupervised fine-tuning does not require labeled data.
Instead, the LLM is trained on a massive dataset of unannotated text from the target domain, allowing it to refine its understanding of domain-specific language through statistical analysis of word relationships and contextual patterns.
Though this method is useful for applying LLMs to specialized fields (law, medicine), it may lack accuracy for specific tasks such as classification or summarization.
Supervised fine-tuning (SFT)
Supervised fine-tuning is used to prime the model to generate responses in the desired format. SFT trains a large language model on labeled data curated for the target task. Through the analysis of the SFT dataset, LLMs learn to identify, categorize, and predict patterns, boosting their efficiency in structured tasks such as classification, summarization, and named entity recognition.
This approach is widely employed to tailor LLMs for complex tasks by training them on carefully curated labeled datasets. Optimal SFT implementation, however, typically requires collaboration among a substantial team of domain specialists who contribute to data annotation, prompt engineering, and comprehensive validation of model outputs.
Instruction fine-tuning
Unlike unsupervised fine-tuning or SFT, instruction fine-tuning focuses on guiding a large language model through natural language instructions. This method is particularly effective for developing specialized AI assistants, such as customer support chatbots designed for specific organizations.
Large language model lifecycle
Here comes the overview of a full LLM lifecycle:
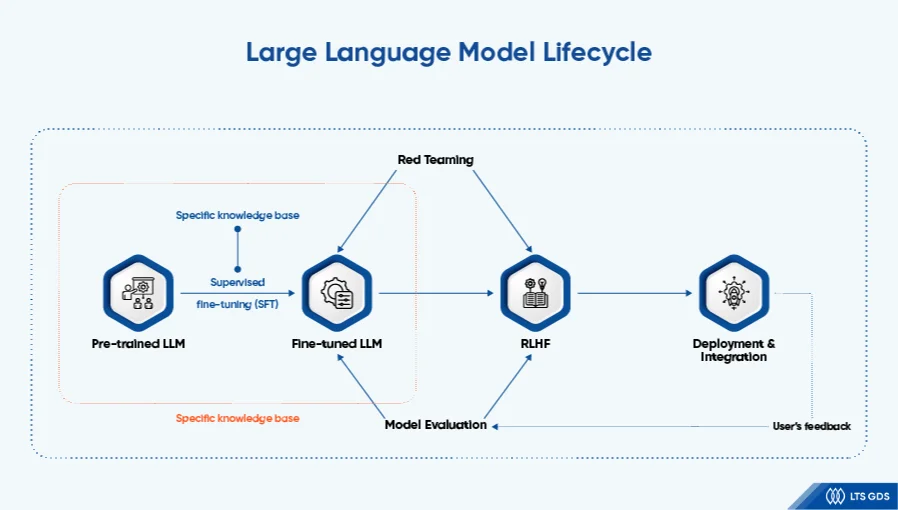
Large language model lifecycle
After fine-tuned LLMs have been examined, the focus shifts to the role of fine-tuning within the broader LLM lifecycle. This process unfolds across several critical stages, each playing a vital role in shaping the model’s capabilities, performance, and adaptability. These stages include
- Pre-training
- Fine-tuning
- Evaluation and benchmarking
- Deployment and integration
- Reinforcement learning from human feedback (RLHF)
- Continuous updates.
Among these, fine-tuning is regarded as a key phrase, enabling a pre-trained model to be transformed into a specialized system tailored for specific tasks. As a result, fine-tuned LLMs are better optimized for subsequent evaluation and refinement.
Data Labeling for Fine-tuning LLMs
Role of data labeling in fine-tuned LLM projects
Without structured data labeling, fine-tuned LLMs risk producing inconsistent or misleading outputs, reducing their effectiveness in real-world applications.
Data labeling for fine-tuning LLMs involves annotating pre-training datasets to create supervised fine-tuning datasets, which are essential for fine-tuning. Under the evaluation and adjustment of human experts, SFT enables LLMs to perform tasks that not only follow syntactic rules but also align with specific industry requirements.
Fine-tuning LLMs require high-quality data labeling to improve their contextual understanding, domain specialization, and response accuracy. Properly labeled data refines these models, making them more effective in natural language processing (NLP) tasks, including sentiment analysis, machine translation, chatbot development, and code generation.
Types of labeled data used in fine-tuning LLMs
Various types of labeled data contribute to refining an LLM’s ability to process and generate human-like text while maintaining industry-specific accuracy:

Types of labeled data used in fine-tuning LLMs
Text classification
It involves categorizing text into predefined labels, making it essential for applications such as sentiment analysis, topic modeling, and spam detection. By training on labeled text datasets, LLMs can distinguish between different sentiments (positive, neutral, or negative) or classify text into categories such as product reviews, news topics, or customer inquiries.
Named entity recognition (NER)
It is the process of identifying and classifying proper nouns, dates, locations, organizations, and other key entities within a text. This type of labeled data helps LLMs extract critical information from unstructured content, making it valuable for applications in financial analysis, legal document processing, and healthcare diagnostics.
Intent classification
This focuses on understanding the user’s purpose when interacting with AI-driven chatbots, virtual assistants, or search engines. By analyzing conversational data, LLMs can differentiate between user intents such as requesting information, making a purchase, or seeking troubleshooting assistance.
Code labeling
Code labeling is the process of analyzing, annotating, evaluating, or modifying programming-related outputs to build supervised fine-tuning datasets for large language models such as GitHub Copilot, StarCoder2, and Code Llama. This ensures the quality, accuracy, and logical coherence of code snippets, dialogues, questions, and answers in programming. Additionally, it improves user experience when interacting with coding support systems. The types of code labeling include:
- Answer generation: crafting responses based on prompts and providing suggestions that reflect a human perspective, avoid AI-generated content, and precisely address given prompts.
- Prompt verification: defining the task scope, language, keywords, and context to support the evaluation of multiple-choice questions.
- Dialogue generation: creating dialogues with manually written questions and answers, with answers revised as needed for accuracy and coherence.
- Dialogue check: reviewing and editing dialogues to refine grammar, human tone, knowledge accuracy, and code structure.
- Dialogue evaluation: assessing dialogues based on predefined criteria, such as quality, complexity, logic, code formatting, and coherence.
- Prompt + answer generation: creating questions and answers, categorizing them appropriately, revising responses if needed, and generating additional questions.
- Prompt + answer verification: evaluating prompts and answers against key criteria like code quality, logic, task scope, language, category, and knowledge cutoff date, using a multiple-choice format.
- Coding evaluation: assessing three core components—instruction (user requirements), plan (step-by-step approach), and solution (implementation).
LTS GDS is a leading provider of high-quality code labeling services, trusted by major partners across the APAC region. With nearly two years of experience, our expert team has successfully handled large-scale projects for cutting-edge models like GitHubCopliot, StarCoder2, and Code Llama.

Partner with us to enhance your SFT dataset for LLMs!
How to Fine-tune LLMs with Annotated Data
Fine-tuning LLMs with annotated data requires four steps, including:
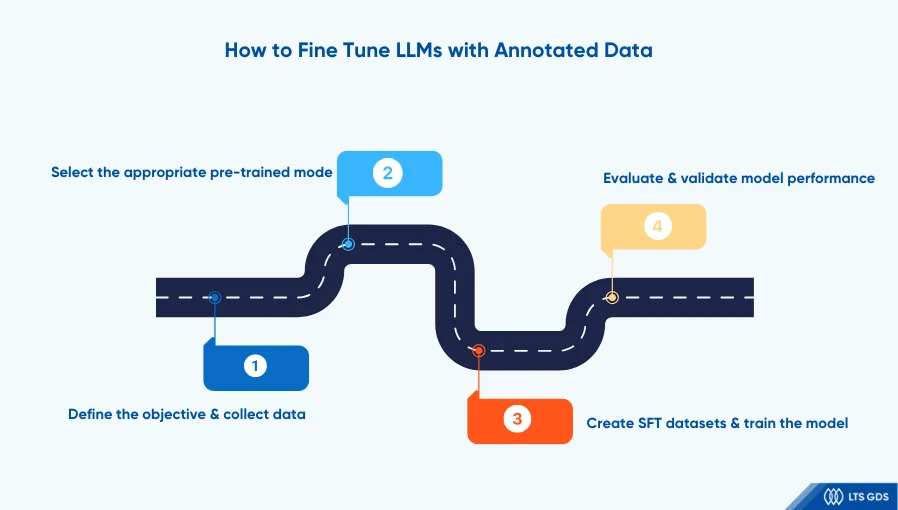
How to Fine-tune LLMs with Annotated Data
1. Define the objective and collect data
Before fine-tuning LLMs with annotated data, the primary objective must be clearly defined. A well-defined goal ensures the selection of an appropriate dataset and annotation strategy. This process begins with gathering insights from clients to identify the specific challenges the model is expected to address.
For example, specific requirements such as 99% accuracy, urgent delivery timelines, or accelerated natural responses achieve 90% effectiveness.
2. Select the appropriate pre-trained model
Understanding model specifications is crucial when selecting a pre-trained model that aligns with your project requirements. This selection serves as the foundation for determining appropriate labeling methods and fine-tuning LLMs approaches, ensuring seamless workflow integration.
Various pre-trained models are available, including BERT, GPT, XLM, StyleGAN, and GauGAN.
Each has different advantages and disadvantages, making your selection dependent on your specific objectives and intended applications.
3. Create SFT datasets and train the model
Data labeling is carried out according to predefined guidelines to create structured supervised datasets for fine-tuning. Once labeled, these SFT datasets are used for training models.
To optimize performance, key parameters (learning rate, batch size, number of epochs...) must be carefully configured before the training process begins.
4. Evaluate and validate model performance
Following training, the model undergoes evaluation using validation datasets to make sure it meets desired parameters and performance expectations. If necessary, additional fine-tuning iterations are conducted to improve model accuracy before deployment.
Best Practices for Data Labeling Process for Fine-tuning LLMs
So, what are the best practices for fine-tuning LLMs?
Fine-tuned LLMs require high-quality supervised fine-tuning datasets tailored to the specific needs of each project. As project requirements can be updated throughout LLM development, the data labeling process must also be continuously adapted to achieve optimal outcomes. Here are some best practices to follow:
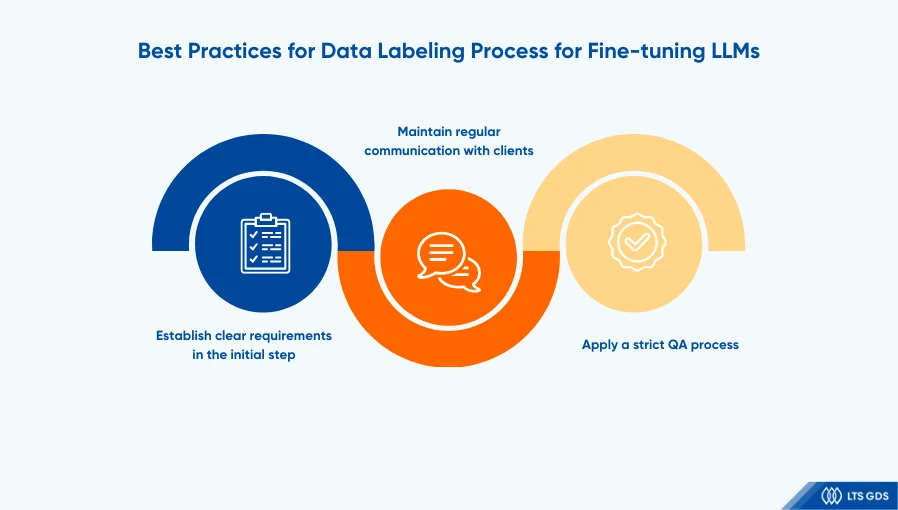
Best Practices for Data Labeling Process for Fine-tuning LLMs
1. Establish clear requirements in the initial step
Defining clear requirements from the outset prevents inconsistencies and minimizes the need for revisions later in the process.
Before the labeling process begins, essential elements such as annotation guidelines, project scope, objectives, and labeling specifications should be clearly outlined.
2. Maintain regular communication with clients
Frequent updates with clients ensure that we have accurately followed their intent and allow for timely adjustments if needed.
This iterative approach reduces misalignment and enhances the quality of the final dataset. Key strategies include:
- Conducting regular check-ins to review progress and address potential challenges.
- Gathering client feedback during implementation to refine accuracy.
- Adjusting labeling strategies based on updated requirements or business goals.
3. Apply a strict QA process
Quality assurance (QA) assumes a pivotal role in minimizing erroneous and potentially misleading information within annotated datasets. The comprehensive QA protocol encompasses multi-level validation processes, automated verification, and rigorous assessment of inter-annotator concordance.
Read more: How to have high-quality data annotation for Machine Learning?
For organizations aiming to optimize their fine-tuned LLMs with high-quality annotated data, partnering with industry-leading experts can make all the difference. Let’s reach out now!

Power Your Large Language Models with Our Experts and High-quality Data!
FAQs about Data Labeling for Fine-tuning LLMs
1. How do fine-tuning LLMs differ from prompt engineering?
Fine-tuning involves retraining an LLM with labeled data to adjust its parameters, making it better suited for specific tasks. Meanwhile, prompt engineering tailors input prompts to generate desired responses without modifying the model itself.
2. How much-labeled data is needed for effective fine-tuning LLMs?
The amount of labeled data needed for effective fine-tuning depends on the complexity of the task, model size, and desired performance improvement. It ranges from thousands to millions of examples. Smaller models and narrow-domain applications may require less data, while general-purpose or large-scale deployments demand extensive datasets.
3. How to ensure optimal quality and consistency in data annotation processes for fine-tuning LLM?
Maintaining quality and consistency in fine-tuning LLM with data annotation requires engaging domain experts, establishing clear guidelines, implementing multi-step validation, leveraging AI-assisted tools, and continuously refining annotation processes through feedback loops.
Accelerate LLM Fine-tuning with High-quality Dataset
Both supervised fine-tuning and data labeling are essential for developing high-quality LLMs. Data labeling serves as the foundation, enabling fine-tuned models to handle domain-specific tasks with efficiency.
By implementing robust data labeling strategies, enterprises can maximize their LLMs’ potential. Investing in high-quality datasets and applying the right fine-tuning techniques accelerates model performance. Since the fine-tuning process requires significant effort to curate world-class SFT datasets, LLM vendors must collaborate with a trustworthy data labeling provider.
Struggling to find a high-quality SFT dataset for your LLM project?
Look no further! LTS GDS specializes in data labeling for fine-tuning LLMs across diverse industries, including finance, ESG, linguistics, manufacturing, coding, and more.

Let’s Build Robust LLMs Together!


