




Chú thích dữ liệu là gì?
Qúa trình gắn nhãn các loại dữ liệu như hình ảnh, video, văn bản, âm thanh được gọi là chú thích dữ liệu, quá trình này giúp máy học nhận dạng các vật thể và từ đó đưa ra các dự đoán trong tương lai.
Tại sao cần chú thích dữ liệu?
Những dữ liệu được chú thích sẽ là phần quan trọng của máy học có giám sát bởi các mô hình máy học này cần một số lượng lớn dữ liệu được chú thích để phát hiện vật thể và đưa ra quyết định. Đó cũng là lý do tại sao chất lượng chú thích dữ liệu là nhân tố hàng đầu tác động đến độ chính xác và mức độ tương quan của các dự đoán.
Một số loại dữ liệu phổ biến
Trong thực tế, có đa dạng các loại dữ liệu cần được chú thích như hình ảnh, video, âm thanh, văn bản và dữ liệu cảm biến 3D:
Hình ảnh
Các hình ảnh cần được chú thích như con người, đồ vật, động vật…Loại dữ liệu này là phổ biến nhất và chiếm tỷ lệ lớn trong các dự án. Đặc biệt trong một số ngành như ô tô tự lái, công nghệ tự động hóa trang thiết bị y tế yêu cầu một số lượng khổng lồ dữ liệu dạng ảnh cần chú thích. Với dữ liệu được chú thích chính xác và hiệu quả, hệ thống AI có thể tự học từ hình ảnh chú thích để vận hành một cách hoàn chỉnh mà không cần sự hỗ trợ từ con người.
Video
Dạng dữ liệu này là những đoạn ghi hình từ camera quan sát được chia nhỏ thành các khung hình. Khác với hình ảnh, video là một chuỗi các hình ảnh liên tiếp nhau, mỗi hình ảnh sẽ có sự thay đổi rất ít so với hình ảnh trước đó. Điều này đòi hỏi nhân viên xử lý dữ liệu phải chú thích cẩn thận và chính xác để thể hiện được tính liên tục của chuyển động trong các khung hình video.
Văn bản
Với dạng dữ liệu văn bản, chữ hay con số ở đa dạng các ngôn ngữ khi được chú thích sẽ giúp máy học hiểu được ngữ cảnh của nội dung qua từng chữ, từng câu, từng đoạn như tên quốc gia, tên người, cảm xúc hay thái độ. Dạng này sẽ được áp dụng phổ biến nhất khi xử lý ngôn ngữ tự nhiên (NLP).
Âm thanh
Những đoạn âm thanh được ghi âm với ngôn ngữ ở mỗi đất nước, vùng miền tự nhiên khác nhau sẽ được chú thích các thông tin liên quan. Âm thanh đó có thể là bất kỳ loại tiếng ồn, âm thanh nào như tiếng khóc, tiếng la hét,… tất cả đã được nghiên cứu và ứng dụng rất nhiều trong lĩnh vực giọng nói AI.
Dữ liệu cảm biến 3D
Loại dữ liệu được thu thập từ cảm biến 3D thường phức tạp hơn dữ liệu từ camera thông thường. Cảm biến 3D có thể hoạt động ngay cả trong bóng tối vì chúng sử dụng nguồn ánh sáng hồng ngoại. Bên cạnh đó, cảm biến 3D có thể ước tính kích thước vật thể có độ chính xác cao hơn camera.
Các kiểu chú thích dữ liệu
Có rất nhiều kiểu chú thích dữ liệu khác nhau trong vô vàn các dự án, tùy thuộc vào yêu cầu của khách hàng và vật thể cần dò tìm sẽ quyết định loại chú thích dữ liệu được sử dụng. Dựa vào loại dữ liệu cần chú thích, công cụ chú thích và kỹ thuật sẽ xác định loại chú thích dữ liệu.
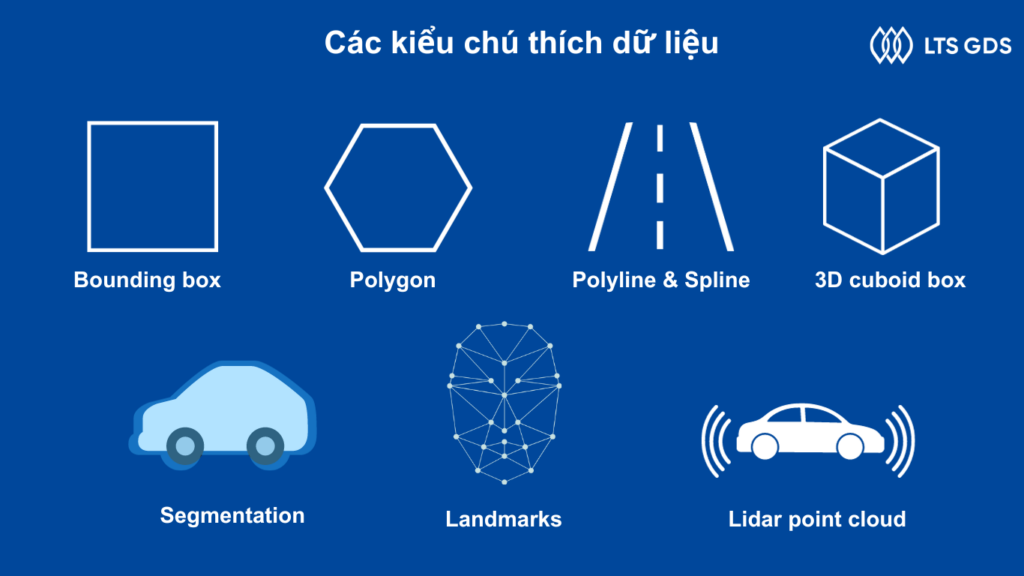
Bounding box
Là một khung hình chữ nhật bao quanh đối tượng trong ảnh. Nó được dùng để xác định vị trí đối tượng, phân loại đối tượng như ô tô, con người hoặc trạng thái. Đây là loại chú thích đơn giản và dễ thực hiện nhất.
Polygon
Với các loại vật thể cần chú thích yêu cầu độ chính xác cao như con người, logo thương hiệu, biển báo đường phố thì một đường đa giác bao quanh vật thể sẽ phù hợp. Đây là loại chú thích dữ liệu linh hoạt nhất để chú thích đa dạng các loại dữ liệu, cung cấp một bức tranh chính xác về hình dạng và kích thước của vật thể, từ đó cho phép máy học đưa ra dự đoán kết quả chính xác hơn.
Polyline & Spline
Loại chú thích này là đường kẻ thẳng có điểm bắt đầu và kết thúc, thường được sử dụng để xác định cấu trúc tuyến tính chi tiết trong hình ảnh, video như làn đường, đường ray và đường ống. Loại chú thích này sẽ giúp máy học trong ngành công nghệ ô tô tự lái có thể phát hiện làn đường và xác định làn đường phù hợp trong quá trình di chuyển.
3D Cuboid
Khối lập phương bao quanh một đối tượng trong hình ảnh 2D, nhằm chú thích vật thể trong không gian 3 chiều với độ sâu của đối tượng. Loại này thường được sử dụng nhiều nhất trong công nghệ xe tự lái, có thể giúp đo khoảng cách đến chướng ngại vật.
Semantic segmentation
Là nhiệm vụ phân vùng từng loại đối tượng nhằm nhận dạng tất cả các pixel thuộc cùng một lớp. Mỗi pixel trong ảnh sẽ được gán nhãn tương ứng bằng các màu sắc biểu thị khác nhau. Sử dụng loại chú thích dữ liệu này giúp thuật toán máy học phân loại các tính năng cụ thể của đối tượng. Một ví dụ tiêu biểu là loại chú thích dữ liệu này được áp dụng cho quá trình kiểm soát quy trình công nghiệp nhằm phát hiện sự thiết hụt hay lãng phí.
Landmark
Với landmark (keypoint), các đối tượng trong ảnh sẽ được đánh dấu các điểm quan trọng nhất. Phương pháp này rất hữu ích để nhận dạng khuôn mặt, cảm xúc, cử chỉ của con người. Nhân viên xử lý dữ liệu có thể sử dụng kiểu chú thích này kết hợp với các loại chú thích dữ liệu khác để tạo bản đồ điểm xác định tư thế của con người.
LiDAR point cloud
Là công nghệ sử dụng ánh sáng ở dạng chùm tia laser để đo khoảng cách giữa cảm biến và đối tượng. Quá trình này sẽ lặp lại hàng triệu lần bởi cảm biến LiDAR, cuối cùng sẽ được thể hiện dưới dạng đám mây điểm. Các đối tượng trong đám mây điểm có thể được chú thích bằng bounding box, khối 3D cuboid…tùy thuộc vào yêu cầu của từng dự án. Loại chú thích được ứng dụng nhiều nhất trong công nghệ xe tự lái.
Các công cụ chú thích dữ liệu phổ biến
Trong các dự án chú thích dữ liệu, một số công cụ phổ biến giúp nhân viên xử lý dữ liệu thực hiện quá trình làm việc hiệu quả hơn như:
- Labellmg
- GIMP
- CVAT
- Label Studio
- V7
- LTS Annotation
- Super Annotate
- RectLabel
- Basic AI
- ViTBAT
3 bước trong quy trình chú thích dữ liệu
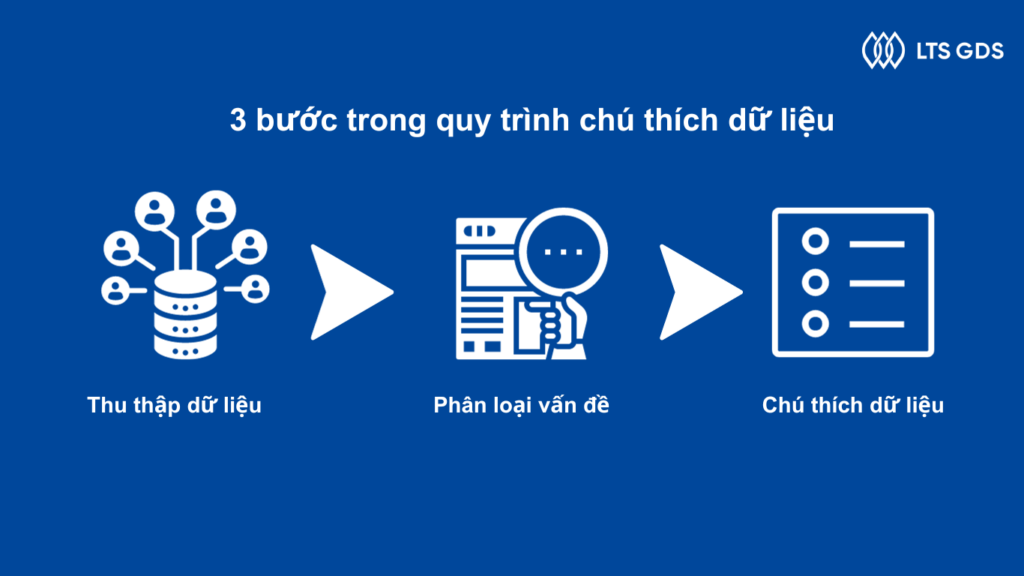
Bước 1: Thu thập dữ liệu
Thu thập dữ liệu là quá trình thu thập, đo lường và phân tích thông tin từ nhiều nguồn cho các mục đích cụ thể. Có nhiều cách để thu thập dữ liệu như nghiên cứu từ khóa trên Google để tìm kiếm và lưu trữ hình ảnh, video. Ngoài ra, có thể mua bản quyền dữ liệu từ các nguồn ảnh hay dữ liệu từ camera công cộng. Hoặc có thể thu thập dữ liệu bằng cách chụp ảnh, ghi âm, quay video. Để thu thập dữ liệu, trước hết cần xác định các loại dữ liệu và phương pháp thu thập để đáp ứng các trường thông tin cần thiết. Hơn nữa, chúng ta cần tập trung vào bài toán đi tìm giải pháp và chất lượng trong các dự án khác nhau.
Bước 2: Phân loại vấn đề
Trước khi lựa chọn loại chú thích dữ liệu phù hợp với dữ liệu đã thu thập, cần xác định yêu cầu của bài toán là gì, đó là phân loại hình ảnh hay phát hiện đối tượng. Xác định rõ vấn đề của từng dự án sẽ giúp dự án tiết kiệm thời gian và ngân sách.
Bước 3: Chú thích dữ liệu
Sau khi thu thập dữ liệu và xác định được vấn đề, dự án sẽ chuyển đến bước chú thích dữ liệu. Nhân viên chú thích sẽ sử dụng các loại chú thích dữ liệu (bounding box, 3D cuboid box, LiDAR point cloud…) để gắn nhãn các loại dữ liệu. Quá trình chú thích dữ liệu có thể được thực hiện bằng các công cụ chú thích tự động hoặc nhân viên vẽ thủ công, mỗi cách sẽ có những ưu nhược điểm khác nhau. Trong khi chú thích dữ liệu tự động nhanh hơn, thì chú thích dữ liệu thủ công sẽ có độ chính xác cao hơn, đặc biệt với dữ liệu phức tạp.
Chân dung đối tác tiềm năng?
Có nhiều yếu tố ảnh hưởng đến chất lượng dữ liệu được chú thích, một trong số đó là việc lựa chọn nhà cung cấp dịch vụ chú thích dữ liệu phù hợp. Các công ty có thể lựa chọn các công cụ chú thích dữ liệu tự động hoặc để nhân viên nội bộ của họ phụ trách. Ngoài ra, các công ty AI có thể lựa chọn các công ty BPO chuyên cung cấp các dịch vụ chú thích dữ liệu chuyên nghiệp.
Đọc thêm: Làm thế nào để lựa chọn được công ty cung cấp dịch vụ chú thích dữ liệu phù hợp?
LTS GDS cung cấp dịch vụ chất lượng cao và bảo mật cho các đối tác với đội ngũ nhân sự tận tâm. Liên hệ với chúng tôi để biết thêm thông tin chi tiết!


